
阿里云有许多很好的技术,比如负载均衡SLB,关系型数据库RDS,云服务器ECS,开放存储服务OSS等。如今又增加了一款重磅云服务产品:基于飞天的ODPS(Open Data Processing Service),提供数据仓库、数据挖掘和其他数据应用等功能。7月14日,阿里云计算公司总裁及阿里巴巴集团副总裁王文彬(花名菲青)为之站场,并称之为“中国进入大数据时代的里程碑”。
对内统一:ODPS是阿里集团唯一的大数据处理平台
从确定自主开发,到2014年1月,阿里云正式发布ODPS服务,整整五年。阿里云工程师们写下250万行代码,不断试错,不断优化,不断打磨。如今,对内:阿里小微金服(支付宝、小贷、保险、基金)已经全线迁入,数据魔方,阿里妈妈广告联盟,广告搜索,点击预测模型训练,淘宝指数,阿里无线,高德,中信21cn等业务都在其上,对外:药品电子监管系统、华大基因也已采用了ODPS。
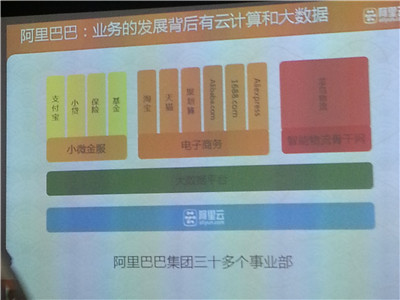
ODPS是阿里集团30多个事业部唯一的大数据处理平台
更有意思的是,4月,为了更好地对ODPS平台上进行算法的调试、测试,阿里巴巴举办了基于ODPS的天池算法竞赛(“天池”平台基于阿里云ODPS的大数据开放平台,向学术界免费提供科研数据和数据处理服务,第一期开放三类科研数据集,包括用户购买成交记录、商品购买评论记录、商品浏览日志记录等,数据经过脱敏处理,所有数据均可由平台应用者使用)。
竞赛的题目是:天猫推荐算法大赛开放竞赛数据:在天猫,每天都会有数千万的用户通过品牌发现自己喜欢的商品,品牌是联接消费者与商品最重要的纽带。本届赛题的任务就是根据用户在天猫的行为日志,建立用户的品牌偏好,并预测他们在将来对品牌下商品的购买行为。
各大高校的参赛者在ODPS平台上进行算法的调试、测试。几个月下来,成绩斐然。阿里云相关负责人对CSDN云计算表示:最优秀的算法比天猫本身数据预测算法效率还高10%!
正是有了这些真实落地的效果,王文彬才更有信心:“ODPS会是阿里集团30多个事业部唯一的大数据平台。这其中既包含已经完全迁入的小微金服,也包含电子商务(淘宝、天猫、聚划算、Alibaba.com、1688.com、AliExpress)、智能物流骨干网(菜鸟物流)在内。涉及到几亿用户的数据,工作量极大,需要慢慢来做。但这一时间点,我相信很快。”
这一计划被阿里内部称之为“登月计划”。其中还有一些小故事。接近阿里云的都知道:阿里云的云梯1,是基于Hadoop的;而云梯2才是自主开发的。阿里内部对于二者的技术争论由来已久。而大家不知道的是,2013年10月,为了融合阿里小贷和支付宝的数据,支付宝希望ODPS团队协助他们搬家,将支付宝数仓业务从Hadoop机群搬到ODPS上,这就是“登月1号项目”。2014年5月,登月1号项目成功,小微金服的全部数据业务开始基于ODPS发展。也正是阿里内部对于“稳定性,安全性,服务能力要求最高”的小微成功迁入,才有了后续覆盖搜索、广告、物流等多个BU的数据统一的计划,才有了“ODPS将成为承载阿里集团全部数据的统一处理平台”的实施。
阿里内部对ODPS评价颇高。
“从Oracle到Hadoop,我们解决了海量数据如何存储和分析的问题,阿里的数据业务不再受制于规模的瓶颈;从Hadoop到ODPS,更是一次质的飞跃,为后续大数据业务的开展扫清了障碍。登月计划共计划了20多个项目,涉及阿里巴巴和小微金服所有的事业部,覆盖集团全部数据人员,其牵扯人员、资源之多,在集团内部罕见。登月计划的全面启动,标志着阿里集团自研的飞天+ODPS平台,从功能和性能上已经渐渐超越了Hadoop,阿里云的技术走在了世界前列。”
对外拓展:主攻结构化数据和半结构化数据,未来支持更多框架
在阿里云的产品规划中,基于飞天,有多类服务:离线的结构化数据存储和计算服务平台——ODPS (Open Data Processing Service),半结构化数据的实时随机读写服务——OTS(Open Table Service),实时流数据处理服务——OSPS(Open Stream Processing Service)等。

ODPS的产品、用户和生态
谈到ODPS能够处理什么类型的大数据,阿里云产品经理汤子楠表示:“ODPS最擅长处理结构化数据,比较擅长处理半结构数据,不能处理非结构数据(当然,最后这点会通过与开源技术合作及其他技术开发来拓展)。”
具体来看ODPS的产品、用户和生态:
产品:SQL、MapReduce、BSP、算法包;安全控制、分享机制
用户:大企业——存储计算能力服务化,专注数据和业于务;
生态:海量计算、准实时计算、流式计算;个人,大数据平民化,数据创新;数据生产者,数据消费者(广告、推荐、客满改进、模式创新),数据加工者(行业专家、咨询公司等)和服务与应用供应商(数据应用、BI等)
其产品优势可以概括为5点:
海量运算触手可得:用户不必关心数据规模增长带来的存储困难、运算时间延长等烦恼,ODPS可以根据用户的数据规模自动扩展机群的存储和计算能力,使用户专心于数据分析和挖掘,最大化发挥数据的价值。
服务“开箱即用”:用户不必关心机群的搭建、配置和运维工作,仅需简单的几步操作,就可以在ODPS中上传数据、分析数据并得到分析结果。
数据存储安全可靠:ODPS采用三重备份、读写请求鉴权、应用沙箱、系统沙箱等多层次数据存储和访问安全机制保护用户的数据:不丢失、不泄露、不被窃取。
多用户协作:通过配置不同的数据访问策略,用户可以让组织中的多名数据分析师协同工作,并且每人仅能访问自己权限许可内的数据,在保障数据安全的前提下最大化工作效率。
按量付费:ODPS根据用户实际的存储和计算消耗收费,最大化的降低用户的数据使用成本。
汤子楠表示:“ODPS所有的功能是以RESTful API的形式对外提供,目前仅支持SQL,其他服务将后续逐一对外开放。而由于ODPS设计之初就是为了对外开放,做基于互联网的多租户的公共数据处理服务,安全性在ODPS的设计和实现中具有优先级很高。未来,ODPS还将开放更底层的逻辑计算单元,支持用户基于ODPS开发Spark、Pig、准实时、流处理等,真正成为在ODPS统一平台可以实现多种框架的大数据运算的乐趣。彻底解决现在数据要从不同集群中导来导入,且没有统一布局,数据处理和维护都的麻烦。”
对于ODPS,阿里云的定位显然不仅是内部的数据统一平台,而且在外部,也将通过合作共建生态,为更多企业提供大数据服务。汤子楠分享了一个用户案例:
药品电子监管平台,收集中国境内每盒药从生产、批发、零售环节的所有流通信息,每盒药都印刷了一个条形码“中国药品电子监管码”。药监部门利用这些流通信息追踪到中国市场上每批药品流向,追溯到零售环节任何一盒药品的来源。而伴随药品数量的急剧攀升和分析等新需求,原有的Oracle系统无法满足需要。新的数据平台基于OTS+ODPS两款产品,关键业务处理的平均延时降低100倍以上,成本大幅降低。
除此以外,还有华大基因,其已经在ODPS上做了基因测序,耗时不到传统方式的十分之一。
最后,ODPS的峰值是100PB数据处理6小时完成。按照使用量付费,存储1GB的数据,ODPS每个月大概是0.5元左右。
技术:ODPS与BigQuery、Redshift+EMR、HPC的比较
从技术上看,对ODPS还有两个疑问。阿里云的回复很到位。
1.ODPS与Google BigQuery、Amazon有Redshift和EMR的比较?
阿里云:Google的BigQuery,Amazon的Redshift和EMR,可以认为是ODPS的类似产品。在国内,ODPS是首款大数据存储和计算开放服务。ODPS和BigQuery的产品形态比较类似,比如都支持海量数据的存储和计算,都支持SQL语法等。两者的主要区别在于:
1)底层技术实现不同。BigQuery基于Google自研的Dremel引擎,而ODPS则基于阿里云自研的飞天系统,两者在存储、任务调度、任务优化上有很多细节都不一样。
2)BigQuery的主要应用场景是交互式BI分析,而ODPS的适用场景则广的多:目前已经开放的SQL功能主要用于数据仓库和日志分析;后续还将开放UDF和Map Reduce,支持用户编程的离线计算;ODPS准实时,支持交互式BI分析;ODPS流处理,支持实时计算等。同时,ODPS的数据授权体系功能更加丰富,使用更加灵活,可以同时满足数据拥有者、数据消费者和数据分析者的需要,ODPS未来可以成长为一个基于数据的生态系统的底层平台。
3)BigQuery仅是一款产品,而ODPS则是阿里云产品线的一部分。除了ODPS之外,阿里云还有SLS、OTS等一系列大数据服务,组成一个综合的大数据解决方案,满足用户在大数据领域的多项需求。
2. ODPS与各个超算中心提供能力的区别?
阿里云:1)超级计算机更适合计算密集型作业,如果是用MPI算核物理、天体物理、蛋白质折叠、求解普通PC上需要几千万年的迭代方程,用超级计算机可能更快。反过来,分布式集群Mapreduce适合IO密集型的作业,加上成本低,可以把集群规模搞得很大,因此最适合扫描过滤海量的数据,例如互联网行业的经典应用:为搜索引擎创建全网Web页面的索引。
2)超级计算机造价更昂贵,维护成本也高,甚至每小时电费就得上万元。
云计算是建立在低成本硬件+牛B的分布式操作系统设计上,在计算灵活性和多任务处理上远超超级计算机,可以更广泛的应用于商业领域,例如阿里云去年和国内的动画公司合作渲染出来的《昆塔》,计算量是《阿凡达》的四倍。随着国内经济的升级,很多造船、石油、材料、生物、天体物理、军事领域的计算需求都很强烈,这一类计算密集型任务,也可以通过云计算完成。
ODPS是可以支撑科学运算的,阿里正在举办的大数据竞赛就依托于ODPS平台。参赛选手大量使用逻辑回归、随机森林这一类的数据挖掘算法。
进一步简单解释一下,基于飞天系统,ODPS实现了Mapreduce(以及更高级的多阶段DAG)、Graph、MPI等编程模型在同一个计算集群上统一调度。因此除了 IO密集型的计算,还能支持计算密集型的迭代计算,例如随机梯度下降。
不过目前阿里云ODPS只对外开放商用了SQL编程接口,更多接口例如Mapreduce、Graph等等还没有进入公测阶段,不过很快就会对外了。
大数据技术生态中,ODPS所代表的的只是其中重要的一环,后续更为重要的是,强化伙伴能力,迅速在更多行业和应用中扎根。期待基于ODPS的扶植计划!
我们一直都在努力坚持原创.......请不要一声不吭,就悄悄拿走。
我原创,你原创,我们的内容世界才会更加精彩!
【所有原创内容版权均属TechTarget,欢迎大家转发分享。但未经授权,严禁任何媒体(平面媒体、网络媒体、自媒体等)以及微信公众号复制、转载、摘编或以其他方式进行使用。】
微信公众号

TechTarget
官方微博

TechTarget中国
作者
相关推荐
-
阿里云在东南亚的经营战略
据一位顶级公司高管称,阿里云在东南亚取得成功的关键是,专注于与当地合作伙伴建立合作关系,以及为各行业客户量身定 […]
-
阿里云成功防御国内最大规模Memcached DDoS反射攻击
上周,阿里云安全DDoS监控中心数据显示,利用Memcached 进行DDoS攻击的趋势快速升温。尽管如此, […]
-
阿里云推出马来西亚城市大脑助力提升城市治理能力
阿里云在吉隆坡一个仪式上宣布同马来西亚发展数字经济的官方机构 — 马来西亚数字经济发展局(MDEC)及马来西亚 […]
-
应对数据大爆炸:阿里云发布新一代云存储引擎2.0
2018年1月9日,阿里云宣布推出全新一代块存储、极速型OSS、NAS Plus等高性能企业级存储产品家族,并对分布式存储引擎进行全面升级,性能比过去提升了最多50倍,给用户带来了从高速到高铁的体验。