
面向服务架构(SOA)是今天被提及最频繁的IT改进模式之一。维基百科将SOA解释为“一种将企业与计算资源连接起来的设计,可以按需达到用户期待的结果”。
如果灾难恢复服务也可以“按需”提供可能会出现一些有趣的现象,比如,企业能够确保RTO(恢复时间目标)在15分钟或更短的情况下,可以不用考虑数据、应用、服务器或存储平台的类型,也无需关心地点和数据集的大小。再比如,不论是在企业的内网还是外网,也不论是在什么时候或什么地点,特定的备份、复制或恢复功能可以随时启用。
这听起来过于理想化?这样的想象终将被今天的高成本和实施限制击碎?本文将描述一种灾难恢复领域的模式转变,转变后的模式可以通过一种普通且与厂商无关的“面向服务平台”为客户提供“按需”的灾难恢复服务。
通过将SOA的原则与技术进步相结合,该平台可以在一个位于服务器与存储系统之上的独立服务层提供关键数据的保护和恢复服务,同时也可以以最低的成本提高与业务连续性相关的RTO和RPO(恢复点目标)。
抛弃旧有方法
传统上,企业的IT部门往往通过结合某一厂商的一个单点解决方案与另一厂商的另一个单点解决方案来实现灾难恢复功能。
如果要实现高等级数据备份,企业需要从某一特定厂商处购买一个高性能存储阵列。要实现安全或数据加密,这往往意味着要购买另一个厂商的单点产品。
这种模式的问题在于,管理或调整这些独立的解决方案将带来不断增加的成本和复杂程度,要通过自定义脚本来统一控制更不可能。假如复制软件与一个特定阵列捆绑在一起,将会产生其它的成本——当用户超过阵列的容量时,将不得不对技术进行更新,升级到更高的容量系统并准备做数据迁移。
假如企业希望自己动手将这些单点解决方案集成起来,形成一个面向服务的灾难恢复架构以提供核心数据服务,这样做所带来的挑战和成本很快就会超过潜在的收益。
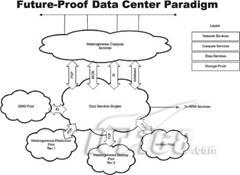
在光纤层,将灾难恢复SOA化
为了使SOA更为自动化,模式转变是必需的。目前缺失的是一种简单却可扩展的方法去提供与核心的灾难恢复相关的数据服务,这种方法存在于连接所有关键服务器及其基础网络存储子系统的存储网络光纤内部。图1描述了在一种称为“数据服务引擎”的集中的云网络提供光纤层灾难恢复服务的情形。
技术进步和虚拟化的不断流行使得企业能够在需要的时候调整这种面向服务的平台,从而能够最大限度地利用光纤提供服务。光纤层的核心数据服务与存储或主机层面的服务相比,具有以下优点:
• 简单化整体基础设施和运营标准;
• 以RTO和RPO的形式达到更高的服务质量和更高的SLA(服务水平协议);
• 降低整体IT资产和运营支出;
• 按需提供更为统一的服务和存储能力;
• 能够为大容量存储提供高水平的可用性和功能;
• 保护各种不同的存储阵列(通常来自不同厂商);
• 更紧密地集成应用,以实现更一致和更迅速的恢复。
一旦企业完成了服务平台的转变,将在多大程度上获得上述的各种好处呢?一家大型财务公司最近完成了这项工程。在转变以后,该企业获得了如下的投资回报:
• 恢复时间获得1200%的提升(RTO从24小时提升至30分钟,RPO提升至零数据丢失);
• 存储成本降低50%,节省了超过250万美元;
• 灾难恢复所需带宽降低了80%;
• 现有存储的利用率提升了80%;
• 总体而言,与转变前的灾难恢复方案相比,该财务公司预计在五年内将节省超过630万美元。
灾难恢复领域的SOA需求
为了达到全面的灾难恢复,SOA应该拥有以下特征:
• 保密性——降低数据在复制或异地存储的泄露风险;
• 降低或减少数据复制——降低带宽和需复制的数据总量;
• 压缩——降低带宽和需复制的数据总量;
• 优化数据变化管理——减低需复制的数据总量;
• 虚拟化功能——允许使用现有存储设备,并能够为未来存储提供更有竞争力的选择;
• 单一操控的灾难恢复管理——使灾难恢复服务更容易启动、管理或修改,应包括集中提供跨越独立基础平台的灾难恢复服务的能力;
• CDP(连续数据保护)——使得企业更容易达到更高的RPO;
• CDR(连续数据复制)——支持变化数据的最迅速的复制;
• 对存储等级的复制支持——支持从主要光纤通道磁盘系统到低成本SATA磁盘系统的高性价比快速恢复。
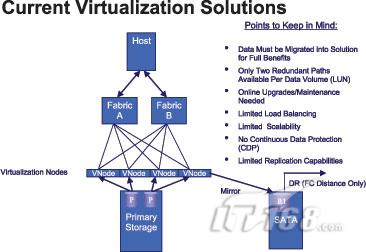
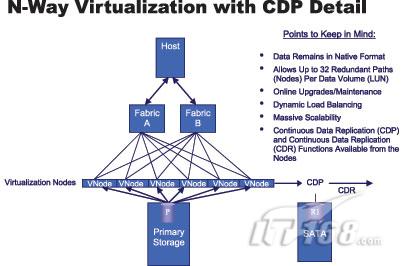
虚拟化:灾难恢复平台背后的“秘密武器”
虚拟化的最新发展使灾难恢复服务平台进行模式转变成为可能。企业服务器及相应的计算资源已经开始为灾难恢复进行虚拟化变革——这得益于某些软件允许在大型物理服务器上进行多“虚拟器”的设计、镜像、保护和恢复,并且所需的物理设备越来越少。
现在,存储虚拟化技术已经成熟到可以在存储“云”网络或光纤层提供可扩展性和容错性——这些都是支持一个稳定的核心灾难恢复相关数据服务平台所必需的。
以往,企业在配置存储虚拟化技术时都非常谨慎。很多虚拟化解决方案都需要将企业现有的数据迁移到虚拟层上,并且如果企业对虚拟化结果不满意的话,很难恢复到原来的样子。另外,虚拟化在实现灾难恢复服务时需要占大量数据缓存,这也会对企业带来连续性、流畅性、可用性等方面带来一定的挑战。
现在,新的存储虚拟化技术已经出现。一些解决方案提供稳定的虚拟化平台,并允许数据作为虚拟池的一部分来操作,这意味着数据可以保持原来的格式和保留在原来的存储设备中,不需要进行任何数据迁移。假如企业需要将数据恢复到虚拟化之前的样子,只需要对光纤区域或映射表做简单的修改就能完成,不需要任何缓存。灾难恢复服务在光纤基础的虚拟化层面仍然可以保持可用性。
图3介绍了存储虚拟化解决方案的能力。该方案设置了带有虚拟化功能和相关的灾难恢复服务的节点,这些节点可以作为透明的虚拟层的一部分。该方案拥有在服务器和存储设备之间以32GB每秒的速度传输数据的能力,并能够在某一节点失效时自动转移到另一节点。现在,这些技术允许CDP或CDR等恢复服务使每一个关键应用中断时快速“启动”,更不用说恢复存在于应用之间的数据了。
这种结果将技术进步与一种更为完美的整体策略结合起来,作为一套与厂商无关的独立模式来提供数据保护、复制和恢复服务。相比限制选择和增加业务连续性成本,这种结合能够更为简单,成本更低廉。
我们一直都在努力坚持原创.......请不要一声不吭,就悄悄拿走。
我原创,你原创,我们的内容世界才会更加精彩!
【所有原创内容版权均属TechTarget,欢迎大家转发分享。但未经授权,严禁任何媒体(平面媒体、网络媒体、自媒体等)以及微信公众号复制、转载、摘编或以其他方式进行使用。】
微信公众号

TechTarget
官方微博

TechTarget中国
相关推荐
-
通过多云自动故障转移强化灾难恢复策略
虽然灾难事件的发生是无法完全杜绝的,但是由灾难事件所导致的业务中断却是可以避免的。通过使用正确的工具和采用合适的测试策略,多云中的主动-主动故障转移可确保企业的一切业务正常运行。
-
灾难来袭:AWS备份恢复你的云
执行着不充足而且过时的灾难恢复计划的企业可能已经深陷危险而不自知。这些服务提供了一种架构,让开发人员可以实现冗余。
-
AWS备份选择:突发灾难事件的克星
AWS公共云基础设施以多种服务和工具的形式为客户们提供了灾难恢复和备份的功能,但是用户们还必须遵守AWS的共享责任模式并使用云开发模块来支持其正常运行时间的需求。
-
事件驱动框架和SOA在空军的应用
空军正在利用SOA来改善数据共享,并实时跟踪战机,美国空军机动司令部的Michael Marek解释了企业可从中学习的经验。