
SSH(Struts2+Spring+Hibernate是最为Java业界熟知的Java EE Web组件层的开发技术。很多人提起Java EE,甚至都会将其误认为就是SSH。无论是书籍还是电子教程,大部分都已经千篇一律,讲解各种标签、配置的用法。许多人包括笔者在内,第一次使用SSH的时候,按照教程的介绍进行开发。繁琐的配置,重复的修改配置,不断定义的参数转换器,真的让笔者苦不堪言。本文对SSH的开发模式尝试了重新定义,按照规约优于配置的原则,利用Java反射、注解等技术,设计了新的一套SSH开发框架,应用该框架,可以大大提高开发效率,笔者多次将该开发框架应用在各种小型SSH Web应用系统之中,屡试不爽。
阅读文章之前,读者需要对SSH的结合开发有一些了解,最好是有实践的经验,特别是对Struts2需要较为了解,掌握Struts2自定义拦截器、自定义验证器等的开发。另外,读者还需要掌握一些前提技术,包括Java反射、Java注解、理解事务隔离级别等。
文章首先进行框架的总体介绍,然后分点介绍各个部分的详细设计。另外,文章还将列举该框架中采用的技术特点及其相应目的,希望读者可以从中获益。
框架总体介绍
文章之所以说框架是通用的,因为它的思想适应任何的业务需求。按照文章介绍,按照介绍的框架搭建完代码架构后,可以屏蔽许多技术细节,让开发人员专注于业务逻辑的实现,这些繁琐的技术细节包括技术配置、权限控制、页面跳转、错误处理等等。框架大致的风格如图1所示,总体来说,该框架遵守了“规约优于配置”的原则。
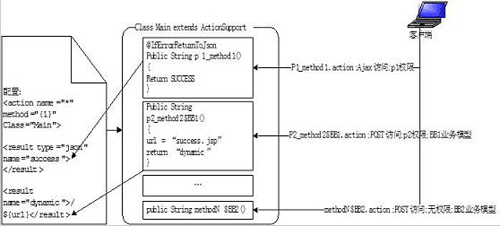
图 1. 框架大致风格
上图中,系统只有一个action配置。每个业务操作,不再对应一个ActionSupport子类,而是对应一个ActionSupport子类的类方法,利用Struts2的动态方法特性,使得业务方法摆脱了繁琐的配置,方便的增加和删除。全面的 result 配置,解决了各种页面跳转的问题。Action方法的起名,遵守了权限与业务模型规约,让模型选择与权限控制交给框架来实现,同时访问的操作名就是【方法名】.action。下面,将一一对框架的各部分进行讲解。
Struts2的不动配置
该框架中,我们建议只定义少量的类继承于ActionSupport,这样可以使得struts.xml的配置尽量减少,甚至只进行少量配置,而不用随着业务的增加而修改配置。清单 1 是笔者为一个教师考勤系统定义的Action配置。
清单 1. Struts2的配置清单
| 以下是引用片段: <action name=”*” method=”{1}” class=”Main”> <interceptor-ref name=”fileUpload”> <param name=”maximumSize”>4073741824</param> </interceptor-ref> <interceptor-ref name=”myInterceptorStack”></interceptor-ref> <result name=”input”>/noDir/error.jsp</result> <result type=”json” name=”success”></result> <result name=”errorJson” type=”json”></result> <result type=”json” name=”error”></result> <result type=”stream” name=”stream”> <param name=”contentType”>${contentType}</param> <param name=”contentDisposition”>fileName=”${inputFileName}”</param> <param name=”inputName”>inputStream</param> </result> <result name=”dynamic”>/${url}</result> <result name=”otherAction” type=”redirectAction”>/${url}</result> <result name=”red” type=”redirect”>/${url}</result> </action> |
清单 1 定义了很多规则。首先,该配置使用了动态方法调用技术,这可以使得许多的 Action 方法可以声明到一个类里,不用重复定义Action类,同时对业务的增加和删除可以简约到对Action类里方法增加和删除,增加的Action方法不需进行其他配置,如果业务被删除,则只需要将方法注释或者删除,非常方便。第二,配置的package继承于json-default,也就是说这个包里的action是支持Ajax调用的,默认的,如果返回ERROR、SUCCESS,则会将Action序列化为JSON返回到客户端。我们定义了各种的跳转类型,包括重定向到页面(具体的页面由Action里的url指定)、重定向到Action、重定向到错误页面、流类型的返回等等,这为我们动态的选择返回结果数据提供了方便。那么使用上述的配置,对我们开发有什么好处呢?假设有一个新的业务,我们只需要在Action添加新的方法,如清单2所示。
清单 2. 添加新业务方法
| 以下是引用片段: public String business() throws Exception { …business process… if (has error) { addFieldError(“error message”) return INPUT; } else { //url是action中定义的一个String变量,指定跳转地址 url = “business.jsp”; return “dynamic”; } } |
调用这个新的业务方法,只需要调用这个链接:http://{host}:{port}/{webapp}/business.action。正如我们看到的,定义了新的业务逻辑方法,我们没有修改或添加任何配置,因为我们的配置是完整的,考虑到了各种跳转、错误情况,同时动态方法调用特性,让我们可以动态的指定业务方法。如果我们对清单2中的跳转代码进行抽取,清单2会更加简单。如清单3所示。
清单 3. 抽取基础方法后的业务方法
| 以下是引用片段: public String business() throws Exception { …business process… if (has error) { return redirectToErrorPage(“error message”) } else { return redirectToPage(“business.jsp”); } } |
上面的清单中,我们抽取了redirectToErrorPage和redirectToPage 方法,这样就可以使得其他的业务方法可以重用这些跳转方法,整个业务过程变得清晰易懂。类似的我们还可以抽取出redirectToAction(跳转到另一个业务方法)、redirectStream(流类型的跳转)、redirectToAnotherPage(用于重定向的跳转)、redirectToJson(Ajax的跳转)等等。这样这些公共方法就可以让其他的开发人员一起使用。程序员可以从跳转、错误提示、重复配置Action的痛苦中解救出来,专注于编写业务逻辑。
ModelDriven的规约
有了上面的配置,我们还不能做到完全脱离配置。比如,我们定义了一个Action类继承于ActionSupport,我们知道使用ModelDriven可以将用户上传的数据封装到一个业务Bean里,而不用直接在Action里声明变量,这很重要。我相信有很多读者遇到过这个问题。当业务Bean不同时,也就是需要用户上传的数据不同时,我们就要随之添加新的Action,这直接导致修改struts.xml的配置,然后还要修改applicationContext.xml的事务配置、Bean的配置,哪天我们不要这个业务了,又要重复的修改删除配置,笔者开始时为此事近乎抓狂,为什么我们不能只定义一个Action,而ModelDriven的模型动态改变呢?
仔细考虑Struts2的机制,Struts2将客户端的参数装配到ModelDriven的模型里,是通过“装配拦截器”装配的。只要我们在装配拦截器执行前,改变ModelDriven里的模型对象就行了。这就需要我们自定义一个拦截器,struts2提供了这个机制。在自定义的拦截器里,我们根据用户调用的Action方法,新建一个模型,并且将模型设置到Action中,这样模型就可以是动态的了,记住,这个拦截器需要放在defaultStack的前面。
同样,新的问题是如何根据Action方法动态的选择业务模型呢?难道重复的写if方法吗?当然不能这样,动态的模型,就应该来自于动态的方法。因此定义的 action 方法需要有规约,笔者在自己的程序中,是这样定义规约的。Action方法是这样组成:_$_,使用美元符隔开(美元符是Java方法合法的标识符),前部分是操作名,可以任意取,后部分是业务模型的类名。同时,所有的业务模型,都放到指定的一个包里,假设该包名为com.dw.business。那么在自定义的拦截里,我们获得用户调用的Action方法名,按美元符隔开获得后半部分的类名,指定的包名(这里是com.dw.business+类名就是业务模型类的全路径,使用Java反射机制动态生成一个空的业务模型对象(所以,业务模型类必须有一个无参的构造函数),设置到Action里,再交给装配器的时候,装配器会自动组装这个模型。该拦截器的核心代码如清单 4 所示。
清单 4. 拦截器清单
| 以下是引用片段: public String intercept(ActionInvocation ai) throws Exception { ai.addPreResultListener(this); Main action = (Main)ai.getAction(); //业务方法名 String name = ai.getInvocationContext().getName(); int lastIndex = name.lastIndexOf(“$”); if (lastIndex != -1) { try { String head = “com.dw.business.”; String className = name.substring(lastIndex+1, name.length()); //关键:动态设置业务模型 action.setModel(Class.forName(head).newInstance()); } catch (Exception e) {} } return ai.invoke(); } |
有了上面的配置,基本可以做到屏蔽大多数技术细节开发了,但是我们还有一个问题,当在业务方法中,意外抛出了异常,struts2默认的是返回INPUT,按照 清单1的配置,发生错误将跳转到noDir/error.jsp页面,显示错误信息,这适合在非Ajax的处理。但是有时候我们希望他返回错误是JSON类型,因为 Action的一些方法是Ajax的调用方式,也就是Action方法的执行结果需要返回errorJson。我的解决方法是利用Java注解技术,定义一个新的注解,名为 IfErrorReturnToJson,它的代码如清单5所示。
清单 5. IfErrorReturnToJson的代码
| 以下是引用片段: @Target(ElementType.METHOD) @Retention(RetentionPolicy.RUNTIME) public @interface IfErrorReturnToJson { } |
该注解作用在方法上,也就是Action的业务方法,如果我们希望某业务方法在发送错误时,就返回JSON类型,那么我们只需要在该方法上加上这个注解。现在,我们如何动态的修改返回值呢。清单2的第二行,为ActionInvocation添加了PreResultListener,这个监听器是在返回结果前进行一些处理,正符合我们的需求。我们为自定义拦截器类实现了PreResultListener接口,实现了接口方法,如清单6所示。
清单 6. PreResultListener 的代码
| 以下是引用片段: public void beforeResult(ActionInvocation ai, String result) { if (Main.INPUT.equals(result) || Main.ERROR.equals(result)) { try { String methodName = ai.getInvocationContext().getName(); Method method = Main.class.getMethod(methodName); if (method != null && method.getAnnotation( IfErrorReturnToJson.class) != null) { ai.setResultCode(Main.ERROR_JSON); } } catch (Exception e) { } } } |
可以看到,我们在返回结果前,如果当前的返回结果是INPUT或者ERROR,我们会使用反射机制,检查该方法是否加了IfErrorReturnToJson的注解,如果加了注解,则调用ai.setResultCode(Main.ERROR_JSON);方法,修改返回值,使得结果为JSON数据类型。
事务隔离级别的规约
在SSH开发中,需要重点考虑的是Spring的事务配置。根据不同的业务,定义的事务隔离级别就不同,比如对隔离级别要求高的,就要用到Spring的序列化读的隔离配置;有一些方法只是为了权限控制,用于页面跳转,则不需要用到事务控制;一些操作目的是搜索,那么该事务就是只读的。精细的事务配置,可以提高业务处理的代码效率。这时候,业务方法的命名规约就可以起到隔离级别的控制作用,比如方法名是*begin*(方法名中包含 begin),则该方法没有事务控制;方法名是*search*的,则该方法拥有只读的事务;方法名是*seri*,则用序列化读事务控制,提高并发安全级别。这个事务配置清单如所示。
权限规约
在一些应用中,涉及到简单的权限管理。读者可能会想到一些开源的中间件,如ralasafe这样的开源权限组件,虽然很全面,但是学习起来需要一定的时间,熟练掌握,并配合SSH开发则更需要细致的学习。当我们只是简单的权限控制时,我们完全可以用到一些规约,来完成用户的权限控制。在我设计的规约中,需要在数据库中定义一张Permission表,代表权限 , 它与用户表是多对一的关系,它至少有两个字段,一个是permissionName,一个是permissionPrefix。permissionName用于描述该权限,而 permissionPrefix 是我们所关心的。我们设计Action的方法,遵守permissionPrefix_actionMethodName$BussinessBean 这样的原则,permissionPrefix前缀代表数据库中权限表的permissionPrefix值, 使用下划线隔开。当用户登录后,会将该用户所拥有的权限列表存放到 session之中。当用户试图访问一个Action Method时,会使用 ModelDriven 的规约 里一样的方法,截取方法名获得该方法允许的访问权限,如果用户的权限列表中包含了该方法的权限,则允许调用,否则不允许调用。这样设计,虽然无法做到数据的访问权限,却可以满足一大部门的功能权限控制。这里需要记住,权限描述可以修改,但是权限的permissionPrefix不能修改,如果方法名中没有权限标识,则代表任何用户都可以访问。类似的,如果一个方法多个权限都可以访问,则可以这样设计方法p1_p2_p3_methodName$BussinessBean,使用多个下划线分割。
合理利用Struts2的传参技术
基于HTTP协议的特殊性,上传到Web服务器的数值都是字符串,而我们的业务模型都是对象类型,有一些还是复杂的业务对象。Struts2提供了Conveter的机制,允许程序员将String转换成复杂的业务对象。但是笔者刚用这个机制的时候,开始的确兴奋,但是随着业务的修改,业务模型的修改,这些Conveter的管理着实让人头疼。因此,本人认为Conveter技术应该尽量少用。我提出了一个新的方法,假设一个业务模型中,里面包含一个 List<People> pids属性对象,People里有一个id属性,我们需要客户端上传People的id列表,放入List<People> pids之中。如果使用 Conveter,我们在客户端需要定义规则,如客户端上传pids=1,2,3,4,6,8。然后服务器端使用Conveter执行分割字符串、新建People对象、设置 ID、添加到列表等一系列操作。听着都头晕不是吗 ? 而且这相对并不安全,对程序员解析字符串的功底要求很高。我们感谢Struts2的传参机制,如果我们这样传参:<input name=”pids[0].id”/><input name=”pids[1].id”/>。这两个input的上传,Struts2会根据上传数据的name,自动组装成List<People>对象,并且赋值给pids,pids[0]代表列表的第0个元素,这用到了OGNL表达式的传参规则,它会自动识别pids是数组还是列表,如果pids默认是空,它还会自动新建一个空的数组或列表。笔者可以查看OGNL的相关教程。合理利用该技术,可以大大缩减传参的难度。
合理使用Struts2的标签
Struts2提供了众多的标签,这些标签大致包括了UI标签、数据标签以及逻辑标签。这里,我们需要理解UI标签与服务器端的数据交互格式,比如checkboxlist标签,传到服务器端就是一个数组,该数组存放的是选定的checkbox列表的数值 , 这比使用iterator标签生成checkbox列表容易获得数据。Doubleselect标签,用于生成2级的级联select,经常使用的是部门-用户的级联。Optiontransferselect标签,用于批量的迁移,比如用于批量的为部门分配用户。使用struts2的标签可以大大减少用户界面的开发,以及使得用户界面到服务器的数据传输方式变得非常简单。
Action的模型验证
Struts2具有一套完善的验证机制,在ActionSupport类里,可以将模型验证方法写在validate*方法里。如果重写了ActionSupport 的validate方法,这个validate会在执行所有 ction Method前调用,执行验证。而自定义的validate*(*是方法名),比如方法名是add,则这个方法名就是 validateAdd),它只会在执行add方法前执行验证。对于数据的验证,笔者建议使用validater文件验证,它更加容易配置和修改,利用现有的验证器,可以减少硬编码验证的痛苦。在上面提到的框架中,由于使用的是动态方法机制,我们需要在Action类所在的包里,新建validator的XML文件,名字是{类名}-{方法名}-validation.xml(如果不是动态的方法,则{类名}-validation.xml就足够了)。最后的结果如图2所示。

图 2. Validator 文件配置结果
具体的配置内容,读者可以搜索Struts2的validation框架教程。
自定义业务模型验证器
Struts2提供的验证器,包括 ate、required、requiredstring等等,这些可以归于数据验证。而对于特定的业务模型验证,则比较复杂,因此,在该框架中,可以自定义一个业务验证器,这是struts2支持的,它负责对业务模型进行验证,比如可以验证用户上传的用户ID的用户是否存在,这可以在很大程度上保证系统的安全性。验证器的代码清单7如下面所示。
清单 7. 业务验证器代码
| 以下是引用片段: public class BusinessValidator extends FieldValidatorSupport { private String property = null; public String getProperty() { return property; } public void setProperty(String property) { this.property = property; } @Override public void validate(Object exist) throws ValidationException { String fieldName = getFieldName(); Object fieldValue = getFieldValue(fieldName, exist); if (fieldValue != null && fieldValue instanceof Integer && ((Integer)fieldValue) <= 0) { addFieldError(“message”, “上传的ID,该数据是不存在!”); } else if (fieldValue == null) { addFieldError(“message”, “上传的ID,该数据是不存在!”); } else { if (exist != null && exist instanceof Main && ((Main)exist).getModel() instanceof IChecker) { Main pa = (Main)exist; IChecker e = (IChecker)pa.getModel(); boolean isRight = e.checkOk(property, pa); if (!isRight) { addFieldError(“message”, “上传的ID,该数据是不存在!”); } else { pa.getPubDao().getHibernateTemplate().clear(); } } } } } |
清单7中,用到一个IChecker接口,需要验证的业务模型需要实现IChecker接口,在接口实现方法中实现业务验证过程,错误的话返回false。
在src目录(或者WEB-INF下的class 目录),添加validater.xml文件,在其他自带的验证器后,添加业务验证器配置,命名为check。
清单 8. 验证器的配置
| 以下是引用片段: <validators> …… <validator name=”check” class=”com.attendance.action.BusinessValidator”/> </validators> |
接下来就可以使用这个验证器,在图2中的validation文件里,添加如清单9的配置。
清单 9. 验证器的使用
| 以下是引用片段: <field-validator type=”check” short-circuit=”true”> <param name=”property”>department</param> <message> 该部门不存在 !</message> </field-validator> |
利用JEE Eclipse生成Hibernate的JPA模型
IBM提供了JEE版的Eclipse,专门用于开发Java EE的应用,它提供了从数据库中生成符合JPA规范的数据模型的能力。Hibernate3以后,支持了JPA规范(不是完全支持,但是已经较为全面),利用JEE Eclipse的生成能力,就可以避免繁琐的hbm文件的配置。同时,JPA的规范里,还可以提供 NamedQuery、OrderBy 等注解,对于复杂的数据库,该规范可以减少开发时间。
UI重用
Struts2的action标签,用于调用某个action。这个标签笔者认为非常有用,尤其体现在UI重用中,比如用户管理中,在很多个界面里,都允许用户信息修改和用户删除,那么我们就可以将用户信息修改和用户删除的页面代码以及JavaScript放在一个JSP里,同时定义一个Action方法(名为A),为这个JSP执行初始化。接下来在允许进行用户修改和删除的界面,都用s:action标签调用这个A方法,设置executeResult为true,将用户修改和删除的代码包含在页面里。这样就实现了Action的重用。如果重用的界面不需要服务器的初始化,这直接使用jsp:include或s:include引用重用的JSP。
小结
本文通过一系列的讲解,讲述了如何搭建一个通用的SSH开发框架,陈述了其中的设计思想,由于篇幅限制,文章只介绍了框架中的重要部分和重要思想,希望读者可以从中获益。由于笔者水平有限,如有错误,请联系我批评指正。
我们一直都在努力坚持原创.......请不要一声不吭,就悄悄拿走。
我原创,你原创,我们的内容世界才会更加精彩!
【所有原创内容版权均属TechTarget,欢迎大家转发分享。但未经授权,严禁任何媒体(平面媒体、网络媒体、自媒体等)以及微信公众号复制、转载、摘编或以其他方式进行使用。】
微信公众号

TechTarget
官方微博

TechTarget中国
相关推荐
-
Spring针对Java 8升级
Java 8刚刚在几周前发布。后来Spring Framework项目负责人发表了题为《企业项目中的Java 8》的文章。文中,指出那些著名的Java EE应用服务器如何不允许轻松升级。
-
软件项目成功:项目的处理
在软件项目成功的因素中有我们谈及了问题域和社区,然这两者并不是软件项目本身。你可以把分类当作问题领域连续讨论几个星期,但分类的问题跟实际执行分类的库并不一样。
-
软件项目成功的问题域、社区及细节
在本系列的第一部分中,我们提到了项目成功相关的一些术语,并大致罗列了一组跟项目成功相关的东西……尽管从某种程度来说“提到”意味着“彻底无视”。
-
Rails 4.1改进启动时间和响应布局
在经历了两个候选版本后,Rails团队刚刚发布了Rails 4.1.0。以“单点版本(point release)”发布意在说明更改向后兼容,可以无痛升级。