
在如何至始至终保持代码的可维护性方面我给.NET开发者团队的最好建议是:将应用程序中的每个命名空间都当作组件看待,同时确保组件之间不存在依赖环。 通过遵守这条简单的原则,大型应用系统的结构就不会陷入大块意大利面式代码的混沌之中——而这种意大利面式代码在专业企业应用开发中往往被视为正常而非异常的现象。
相关厂商内容
命名空间即组件
从十多年前.NET技术出现以来,Visual Studio开发工具一直隐式地将VS项目作为组件(也即程序集)。这是不恰当的,因为组件应该是结构代码的逻辑部件,而程序集应该是包代码的物理部件。这导致了另一个被视为正常而非异常的现象:有些企业应用程序竟由几百个VS项目组成。
我为什么鼓励使用命名空间这个轻量级概念来定义组件边界呢?其好处如下:
更轻量的组织:多用命名空间而少用程序集意味着所需的VS解决方案个数和VS项目个数变少了。
减少了编译时间:每个VS项目都会在编译时产生额外的时间开销。具体点说,项目很多的话会导致编译需要花几分钟时间,但如果大幅减少VS项目的数量,则编译仅需花几秒钟时间。
更轻量的部署:部署几十个程序集要比部署上千个简单多了。
更少的应用程序启动时间:CLR加载每个程序集时都需要付出一小些额外的性能开销。加载几十或上百个程序集的话,总共的开销就相当明显了,达到了以秒记的级别。
方便了组件的层次组织:命名空间能够表达出层次结构,程序集则不能。
方便了组件的细颗粒度化:存在1000个命名空间不是什么问题,存在1000个程序集就是个问题。选择构建一些非常细粒度的组件不应该因为需要专门创建相对应的VS项目而令人扫兴。
依赖环危害不小
组件间的依赖环会导致出现人们常说的意大利面式代码(spaghetti code)或者纠缠式代码(tangled code)。假如组件A依赖于B,B依赖于C,而C依赖于A,则A不能够离开B和C单独进行开发和测试。A、B和C形成了一个不可见环,一种超级组件。这个超级组件的开销要比A、B和C三者的开销之和还大,这就是所谓的规模不经济现象(diseconomy of scale phenomenon)(请参见详尽文档 Software Estimation: Demystifying the Black Art by Steve McConnell)。通常,这会导致开发最小单元代码的开销呈指数级增长。这意味着,如果不能将1000行代码划分成相互独立的两份500行的代码的话,开发和维护1000行代码的开销要比500行多出三或四倍。如果是碰到意大利面式或者纠缠式代码的话,那就可能无法维护了。为了使组织架构更加合理,人们应该确保组件之间不存在依赖环,同时确保每个组件的大小是合适的(500至1000行之间)。
对战设计侵蚀(design erosion)
五月份发布的NDepend版本4引入了应对应用程序环的新特性,在这里我想讨论下其所具有实践意义。
现在我们能够按照LINQ查询要求来实现编码规范(我们称之为CQLinq),我们能够利用LINQ的巨大灵活性构建出特定规范。其中一个我参与构建的规范是能够报告命名空间依赖环的代码规范。例如,如果我们来分析.NET Framework v4.5,观察程序集System.Core.dll内部,就会发现其存在两个命名空间依赖环,这两个环都由7个命名空间组成。代码规范特性可以索引环中的某个命名空间(随机选取)并展现这个环。用鼠标左键点击下图cycle字段可以查看依赖环所包括的命名空间:
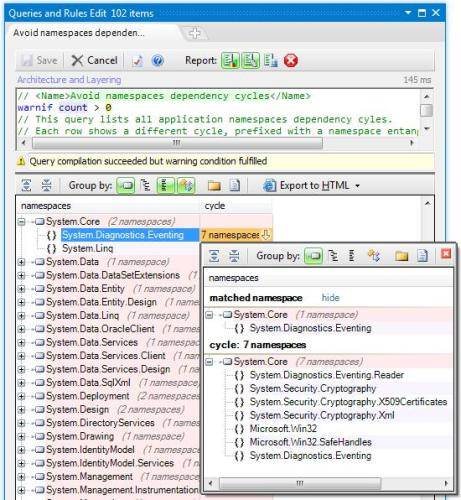
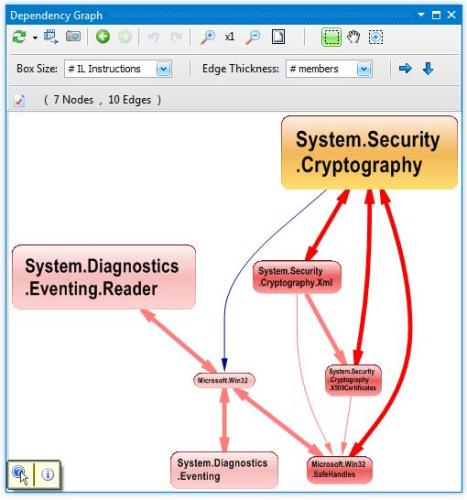
通过鼠标右键点击命名空间列表或者依赖环本身,就会出现将他们导出为依赖图(dependency graph)或者依赖矩阵(dependency matrix)的菜单。下面的截图显示了7个相互纠缠的命名空间。但这不是循环依赖的典型图示,典型的情况是:假定两个命名空间A和B,通过B可以访问到A,并且反之亦然。显然,这样纠缠起来的代码是不容易维护的。
让我们来看看CQLinq的代码规范体 避免命名空间依赖环。我们可以看到开头有很多描述如何使用的注释。这是通过注释和C#代码和读者交流的好机会,感谢即将发布的Roslyn compiler as services,我相信所提倡的简短C#代码摘录(excerpt)而不是DLL或者VS项目,将会越来越受欢迎。
| // <Name>避免命名空间依赖环</Name> warnif count > 0 // 这个查询列出了应用程序的所有命名空间依赖环。 // 每一行显示一个不同的环,并以缠在环中的命名空间作为前缀。 // // 想要在依赖图或依赖矩阵中查看某个环,右键点击 // 该环然后将相应的命名空间导出为依赖图或依赖矩阵即可! // // 在矩阵中,依赖环以红色方块或黑色单元格表示。 // 为了能够方便地浏览依赖环,依赖矩阵需有该选项: // –> 显示直接和间接依赖 // // 请阅读我们关于分解代码的白皮书, // 以更深入地了解命名空间依赖环,以及弄明白为什么 // 避免出现依赖环是组织代码结构的简单而有效的解决方案。 // http://www.ndepend.com/WhiteBooks.aspx // 优化:限定程序集范围 // 如果命名空间是相互依赖的 // – 则它们必定在同一个程序集中被声明 // – 父程序集必定ContainsNamespaceDependencyCycle from assembly in Application.Assemblies .Where(a => a.ContainsNamespaceDependencyCycle != null && a.ContainsNamespaceDependencyCycle.Value) // 优化:限定命名空间范围 // 依赖环中命名空间的Level值必须为null。 let namespacesSuspect = assembly.ChildNamespaces.Where(n => n.Level == null) // hashset用来避免再次遍历环中已经被捕获的命名空间。 let hashset = new HashSet<INamespace>() from suspect in namespacesSuspect // 若注释掉这一行,则将查询环中的所有命名空间。 where !hashset.Contains(suspect) // 定义2个代码矩阵 // – 非直接使用嫌疑命名空间的命名空间的深度。 // – 被嫌疑命名空间非直接使用的命名空间的深度。 // 注意:直接使用的深度等于1。 let namespacesUserDepth = namespacesSuspect.DepthOfIsUsing(suspect) let namespacesUsedDepth = namespacesSuspect.DepthOfIsUsedBy(suspect) // 选择使用namespaceSuspect或者被namespaceSuspect使用的命名空间 let usersAndUsed = from n in namespacesSuspect where namespacesUserDepth[n] > 0 && namespacesUsedDepth[n] > 0 select n where usersAndUsed.Count() > 0 // 这里我们找到了使用嫌疑命名空间或者被嫌疑命名空间使用的命名空间。 // 找到了包含嫌疑命名空间的环! let cycle = usersAndUsed.Append(suspect) // 将环中的命名空间填充到hashset。 // 需要使用.ToArray() 来推进迭代过程。 let unused1 = (from n in cycle let unused2 = hashset.Add(n) select n).ToArray() select new { suspect, cycle } |
代码规范体包括若干区域:
首先,利用属性IAssembly.ContainsNamespaceDependencyCycle以及属性IUser.Level,我们可以尽可能地消除掉多余的程序集和命名空间。因此,对于每个包含命名空间依赖环的程序集,我们只保留了被称为嫌疑命名空间(suspect namespaces)的集合。
定义的范围变量(range variable)hashset被用来避免由N个命名空间构成的环被显示N次。注释掉这行代码where !hashset.Contains(suspect)则会将依赖环显示N次。
该查询的核心是对两个扩展方法 DepthOfIsUsing() 和DepthOfIsUsedBy()的调用。这两个方法非常强大,因为他们各自创建了 ICodeMetric<INamespace,ushort>对象。通常,如果A依赖于B,B依赖于C,则DepthOfIsUsing(C)[A]的值等于2,DepthdOfIsUsedBy(A)[C]的值也等于2。基本上,如果存在一个或多个嫌疑命名空间B使得DepthOfIsUsing(A)[B] 和DepthOfIsUsedBy(A)[B] 的值同时非null且为正数,则包含嫌疑命名空间A的依赖环就会被检测到。
接着我们只需构建命名空间B的集合,然后将它附加上命名空间A,从而使整个环包含A。
裁剪依赖环
虽然我们拥有了检测和可视化命名空间依赖环的强大方法,但当遇到要定义到底哪个依赖必须被裁剪掉以得到层级的代码结构时,我们又一次懵了。让我们来看一看上面的截图,我们可以看到依赖环大多都是由相互依赖的成对命名空间组成的(由图中的双向箭头表示)。想要得出层级的代码结构,首先必须解决的问题是确保不存在相互依赖的组件对。
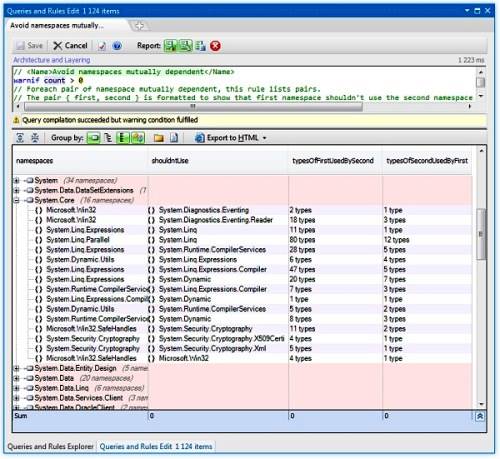
于是我们研发出了CQLinq的被称为避免命名空间相互依赖的代码规范。这个代码规范不仅能够陈列出相互依赖对,同时它还能指示双向依赖的哪一方应被裁剪掉 。这个指示是由所使用的类型个数推断出来的。假如A使用了B的20个类型,而B使用了A的五个类型,很可能的结论就是B不应该引用A。B正在使用A的五个类型,很可能就是由于开发者不清除代码结构而造成的意外情况。这就是代码结构侵蚀的根源。
凭我们的经验,当A和B相互依赖时,我们通常会自然地知道哪一方应该被裁剪掉。这是因为,如我们所想,偶然造成的依赖在个数上通常是较低的。但是如果一直不加以修复,而让这种偶然错误积累,则最终会导致出现我们在大多数企业应用中看到的大面积意大利面式代码。
给个具体的例子,下图是将我们的代码规范应用于程序集System.Core.dll的结果。我们看到这个程序集包含了16对相互依赖的命名空间。同时,下图还验证了前面分析的结果:大多数依赖对中双方间的引用类型个数是很不对称的:
下面展示了CQLinq代码规范的主体,其和上面论述的代码规范有相似之处。如果你仔细看了前面解释的代码规范,并且清楚C#语法,则看懂这条规范的相关代码是件很容易的事情。
我们一直都在努力坚持原创.......请不要一声不吭,就悄悄拿走。
我原创,你原创,我们的内容世界才会更加精彩!
【所有原创内容版权均属TechTarget,欢迎大家转发分享。但未经授权,严禁任何媒体(平面媒体、网络媒体、自媒体等)以及微信公众号复制、转载、摘编或以其他方式进行使用。】
微信公众号

TechTarget
官方微博

TechTarget中国
相关推荐
-
.NET架构师:函数式语言做领域驱动设计
Scott一位.NET架构师,同时也是掌握函数式编程的作者,他很欣赏函数式编程,对于Scott来说,面向对象编程的那些概念也很恐怖,比如多态、泛型、继承、协变等。
-
软件开发就像炒股 关键看你怎么选股票!
本文作者Paulo Ortins在这里分享了对于选择哪种编程语言作为软件开发工作的起点的话题,并阐述了自己的观点。
-
增进离岸Java开发效率的十个提示
近日,Cygnet Infotech公司发布了一篇博文,谈到了如何增进离岸Java开发的效率。众多的ISV与软件厂商总是在不断寻找能以最低的代价实现其业务目标的解决方案。
-
Visual Studio 2013增强调试功能
Visual Studio 2013包含了若干诊断特性,能够帮助开发人员有效地调试他们的应用程序。