
Redis是一个开源的,遵守BSD许可协议的key/value缓存系统,并由其高效的响应速度以及丰富的数据结构而闻名。Redis在京东的使用也是非常普遍的,包括很多关键业务上的使用,由于Redis官方集群还未发布,在使用Redis的过程中需要面对Redis的单点问题,京东采用的是一种比较通用的解决方案即由主从备份再加相应的主从切换(在一些场景下可能进行读写分离),使主Redis出现失效的时候可以快速的切换到从Redis上。但Redis目前存在的一个问题是主从复制在遇到网络不稳定的情况下,Slave和Master断开(包括闪断)会导致Master需要将内存中的数据全部重新生成rdb文件(快照文件),然后传输给Slave。Slave接收完Master传递过来的rdb文件以后会将自身的内存清空,把rdb文件重新加载到内存中。这种方式效率比较低下,尤其是在数据量大的情况下,毕竟网络闪断未必丢数据或者说丢的数据只是少部分,但却要为此付出将整个内存数据都重新传输一次的代价。如果能够将闪断过程的更新数据传递给Slave,那么就不需要将Master内存中的所有数据都传递给Slave了。Redis作者在2.8的候选版(以下简称Redis2.8)中已经将这个部分复制的思路实现了。
那么Redis2.4.16的全量复制与Redis2.8的部分复制是如何实现的呢?如下图所示,这5个状态是Slave在主从复制过程涉及到的几个状态,其中REDIS_REPL_NONE是Redis启动时候默认的状态。图1-2所示的四个状态表示站在Master的角度来看,Slave所处于的状态,因为Slave在Master端看来就是一个特殊的client(同理Master在Slave端看来也是一个特殊的client)。

Redis在接收到“slaveof ip port”命令以后,首先会将自身的状态置为REDIS_REPL_CONNECT,表示需要与自己的Master连接,此时Slave并没有与Master做连接。Redis每隔100ms会调用serverCron()函数一次,每10次serverCron()的调用会调用replicationCron()一次,即每1s会调用一次replication()函数。在replication()函数中,会检查Slave的状态,如果是处于REDIS_REPL_CONNECT状态,就会建立syncWithMaster()的事件处理函数,并将Slave的状态改成REDIS_REPL_CONNECTING。syncWithMaster()函数主要是向Master发送sync命令,当该事件处理函数被触发以后会将Slave的状态改成REDIS_REPL_TRANSFER,表示Slave已经准备就绪要接收Master生成的rdb文件。
回到Master的角色,Master发现有一个Slave连接上来,如果此时的Master一个Slave都没有且没有后台快照进程,则启动一个后台进程将当前内存中的数据生成一个rdb文件,同时将Slave的状态置为REDIS_REPL_WAIT_BGSAVE_END状态,表示该Slave等待Master的快照进程结束。在后台进行生成rdb文件的时候,如果有对redis的更新命令,Master会将这些更新命令存到该Slave的buffer中,如果buffer满了会另外开辟list来存储这些更新命令。当后台快照进程结束,Master会将该Slave的状态改为REDIS_REPL_SEND_BULK,同时注册sendBulkToSlave()事件处理函数用于将生成的rdb文件传输给Slave。等rdb传输结束以后,sendBulkToSlave()事件函数会被删除,Slave的状态会被更改为REDIS_REPL_ONLINE,另外再注册sendReplyToClient()事件函数,将Master在快照内过程中的所有更新操作(Slave的buffer里存的命令)发给Slave。
再回到Slave的角色,当Master向Slave传输完rdb文件以后,Slave自身会将状态改为REDIS_REPL_CONNECTED,表示复制已完成,处于与Master保持实时同步的状态。
上述描述的状态转换如图1-3所示,由图中可知,站在Slave角色看,当出现网络中断的时候不管Slave本身是处于REDIS_REPL_CONNECTING、REDIS_REPL_REPL_TRANSFER还是REDIS_REPL_CONNECTED,都会调用相应的处理函数使Slave进入REDIS_REPL_CONNECT状态,这就意味着Slave需要重新向Master发送sync命令,重新进行一次全量同步过程。图中的REDIS_REPL_WAIT_BGSAVE_START状态是在Slave连接上Master的时候(站在Master的角色看),当时Master刚好后台有快照进程且该快照进程生成的rdb不适合直接传给该Slave时出现的状态,则将Slave的状态置为REDIS_REPL_WAIT_BGSAVE_START。如果此时有快照进程且找到了另外的发起快照进程的Slave,只需要将另外的Slave的buffer内容拷贝到该Slave的buffer中,然后直接进入REDIS_REPL_WAIT_BGSAVE_END状态。如果此时没有后台快照进程,Slave直接进入REDIS_REPL_WAIT_BGSAVE_END状态,同时启动一个后台快照进程。
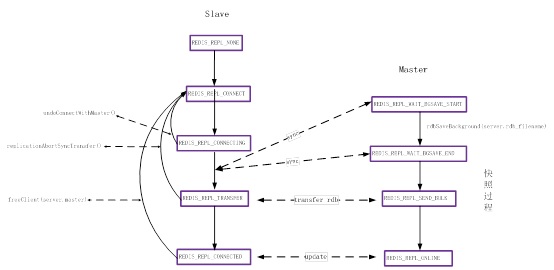
图1-3 Redis-2.4.16主从复制状态转换图
在上述状态转图中存在的最大问题在于任何网络闪断都会导致Slave与Master重连,然后重新进入快照过程,需要花费较长的时间重新传输rdb文件,而Slave在接收完rdb文件以后试图将rdb文件恢复到内存的过程中是不能服务的(除info命令外)。所以提供部分复制至少可以做到在网络闪断且更新命令不太多的情景下能够尽量的避免全量复制的方案就显得尤为重要。
庆幸的是Redis2.8中里已经能够做到在网络闪断的情况下,Slave重新连接上Master以后,仅仅只传输闪断期间的更新命令。在Redis2.8中redisServer结构中增加了一个成员:
char runid[REDIS_RUN_ID_SIZE+1]; /* ID always different at every exec. */
该runid是由一个getRandomHexChars()函数生成的每次不同的一个唯一标识,不同Redis实例之间该runid是不同的,同一个Redis重启以后,其runid和之前的runid也是不同的。
还增加了比较重要的几项数据成员,如图1-4所示:

repl_backlog是redis用于存储更新命令的一块buffer,在部分复制的时候Slave会请求Master从这块buffer中获取闪断情况下丢失的更新操作。repl_backlog在redis启动的时候初始化为NULL,当有Slave连接上来的时候,会被指向创建的buffer,默认为1024*1024(即1Mb)。repl_backlog_size表示该buffer的大小(默认1024*1024,即1Mb)。该buffer是作为一个环形缓存区使用的,当有数据超过buffer的大小以后就会重新从buffer的头部开始写入。repl_backlog_idx表示当前缓存数据的尾部(因为是环形buffer)。repl_backlog_off是全局缓存的偏移量,从开始缓存数据起一直在增长。如果Master一个Slave都没有,则超过一段时间以后repl_backlog会被释放,默认超时时间是1小时。
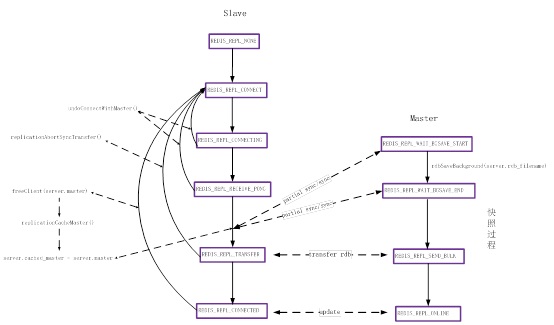
图1-5 Redis2.8主从复制
Redis2.8的主从复制如图1-5所示,Slave如果与Master的连接超时了,Slave会将调用freeClient(server.Master)把连接关闭。该freeClient()函数与2.4版本的相比做了改动,会将Master对应的数据结构的一些信息存起来作为cache Master,其中后续被用于部分复制的最重要的两个信息一个是Master runid,另一个是reploff。reploff是Slave端接收到Master端传递过来的命令以后不断更新记录的全局偏移量的值,该值和Master端的repl_backlog_off对应,正常情况下reploff<=repl_backlog_off。如果Slave尝试部分复制失败以后,就会将该cache Master释放。
Redis2.8中主从复制的过程增加了REDIS_RECIVE_PONG状态,该状态作为试图与Master同步的时候先ping一下的一个中间状态。当ping通以后,Slave首先会尝试部分复制,从cache Master中拿出Master runid和reploff传给Master,表示请求部分复制。第一次的时候,由于Slave端的cache Master是NULL,所以Slave向Master发送的runid是“?”,偏移量是“-1”,当Master收到这两个变量以后会将自身的runid和实际偏移量发送给Slave,同时让Slave发起一次全量同步。
Slave与Master完全同步以后,maste的更新命令会被存到repl_backlog中,同时不断更新偏移量等相关变量。这些更新命令不断地被发送到Slave端,Slave也随之更改自己记录的偏移量。当期间再次有网络断开的情况,Slave会根据记录的runid和reploff向Master请求部分复制,Master检查Slave请求的偏移量对应的内容是否还在repl_backlog中,即比较repl_backlog_off和Slave传递过来的reploff的值的差是否小于等于repl_backlog中实际数据的长度,如果满足条件则将这部分内容发送给Slave,部分复制完成。否则让Slave进行全量复制。
Redis2.8之前的版本没有提供部分复制功能,当出现网络闪断的情况会导致主从之间的全量复制。Redis2.8增加了部分复制功能,在处理网络闪断的情况下是非常有效的,这也是出Redis集群之前需要提供的基本保证。默认1Mb的repl_backlog在访问量大的情况下可能效果未必理想,这个可以通过更改配置文件中的repl-backlog-size的值实现repl_backlog的大小的调整。还有repl_backlog在没有Slave的情况下过多久再释放的时间阈值也可以通过配置文件中的repl-backlog-ttl进行调整。
我们一直都在努力坚持原创.......请不要一声不吭,就悄悄拿走。
我原创,你原创,我们的内容世界才会更加精彩!
【所有原创内容版权均属TechTarget,欢迎大家转发分享。但未经授权,严禁任何媒体(平面媒体、网络媒体、自媒体等)以及微信公众号复制、转载、摘编或以其他方式进行使用。】
微信公众号

TechTarget
官方微博

TechTarget中国
相关推荐
-
redis封装的epoll有什么特点 和平时写的我看用法一样呀?
-
把数据库,redis放到docker容器会有什么弊端吗
-
再造还是塑型:横向伸缩和优化数据资源
在简单的Java应用中运用得好的实践在云的环境里将不会顺利如故。结果许多开发人员都被迫要对熟悉的实践进行重新思考,如数据调用、存储等。
-
松散耦合的七个级别:语义层
最后一级松散耦合是最富有挑战的。即使公司启用服务的实施、契约、策略、流程、基础设施和数据结构等它能想到的所有的变化,每当改变语义时问题仍然出现。