
三种流行web服务的架构
Web服务是一种面向服务的架构的技术,通过标准的 Web 协议提供服务,目的是保证不同平台的应用服务可以互操作。根据W3C的定义,Web服务(Web service)应当是一个软件系统,用以支持网络间不同机器的互动操作。网络服务通常是许多应用程序接口(API)所组成的,它们通过网络,例如国际互联网(Internet)的远程服务器端,执行客户所提交服务的请求。流行的或者曾经流行的Web服务架构有三种:SOAP RPC over HTTP, XML RPC over HTTP和REST over HTTP。下面分别简要介绍这三种架构。
SOAP RPC over HTTP
简单对象访问协议(SOAP,全写为 Simple Object Access Protocol)是一种标准化的通讯规范,主要用于Web服务(web service)中。SOAP 的出现是为了简化网页服务器(Web Server)在从XML数据库中提取数据时,无需花时间去格式化页面,并能够让不同应用程序之间透过 HTTP 通讯协定,以XML格式互相交换彼此的数据,使其与编程语言、平台和硬件无关。
用一个简单的例子来说明SOAP使用过程,一个SOAP消息可以发送到一个具有Web Service功能的Web站点,例如,一个图书价格信息的数据库,消息的参数中标明这是一个查询消息,此站点将返回一个XML格式的信息,其中包含了查询结果。由于数据是用一种标准化的可分析的结构来传递的,所以可以直接被第三方站点所利用。
SOAP RPC over HTTP,在HTTP上传送SOAP并不是说SOAP会覆盖现有的HTTP语义,而是HTTP上的SOAP语义会自然的映射到HTTP语义。在使用HTTP作为协议绑定的场合中, RPC请求映射到HTTP请求上,而RPC应答映射到HTTP应答。然而,在RPC上使用SOAP并不仅限于HTTP协议绑定。SOAP协议没有和HTTP有很好的结合,没有利用 HTTP 协议里面关于request和response 的丰富词汇,而是鼓励应用设计人员定义任意的词汇(动词和名词),像getUsers(),savePurchaseOrder(…),getBookPrice()等。SOAP RPC Request通过HTTP POST请求发送。清单 1 和清单 2 给出了SOAP RPC over HTTP的request和response的示例。请求和响应是封装在SOAP Envelope里面,以HTTP request和response的body传送。
清单 1. A SOAP Request over HTTP示例
| 以下是引用片段: POST /books/bookquery HTTP/1.1 Host: www.Monson-Haefel.com Content-Type: text/xml; charset=”utf-8″ Content-Length: nnn SOAPAction=”” <?xml version=”1.0″ encoding=”UTF-8″?> <soap:Envelope > <soap:Body> <mh:getBookPrice> <id>123456</id> </mh:getBookPrice> </soap:Body> </soap:Envelope> |
从清单 1 可以看出,soap envelope是定义好的格式,它描述所要调用的方法和方法所需要的参数及其参数值,在HTTP上,它作为HTTP request的body发送。
清单 2. A SOAP response over HTTP示例
| 以下是引用片段: HTTP/1.1 200 OK Content-Type: text/xml; charset=’utf-8′ Content-Length: nnn <?xml version=”1.0″ encoding=”UTF-8″?> <soap:Envelope > <soap:Body> <mh:getBookPriceResponse> <result>24.99</result> </mh:getBookPriceResponse> </soap:Body> </soap:Envelope> 从清单 2 可以看出,soap envelope封装了getBookPrice的调用结果,在HTTP上,它作为HTTP response的body返回回来。 |
XML RPC over HTTP
XML RPC over HTTP和SOAP RPC over HTTP从结构上看很类似。这种远程过程调用使用HTTP作为传输协议,XML作为传送信息的编码格式。XML-RPC的定义尽可能的保持了简单,但同时能够传送、处理、返回复杂的数据结构。XML-RPC是工作在Internet上的远程过程调用协议。一个 XML-RPC消息就是一个请求体为XML的HTTP POST请求,被调用的方法在服务器端执行并将执行结果以XML格式编码后返回。清单 3 和清单 4 给出了 XML RPC over HTTP的request和response的示例。请求和响应是封装在一个固定的格式里面,以HTTP request和response的body传送。
清单 3. A XML RPC Request over HTTP示例
| 以下是引用片段: POST /books/bookquery HTTP/1.1 Host: www.Monson-Haefel.com Content-Type: text/xml; charset=”utf-8″ Content-Length: nnn Connection:keep-alive <?xml version=”1.0″?> <methodCall> <methodName>getBookPrice</methodName> <params> <param> <value><string>123456</string></value> </param> </params> </methodCall> |
从清单 3 可以看出,methodcall 是定义好的XML格式,它描述所要调用的方法和方法所需要的参数及其参数值,在HTTP上,它作为HTTP request的body发送。
清单 4. A XML RPC response over HTTP示例
| 以下是引用片段: HTTP/1.1 200 OK Content-Type: text/xml; charset=’utf-8′ Content-Length: nnn Connection: close <?xml version=”1.0″?> <methodResponse> <methodName>getBookPrice</methodName> <params> <param> <value><double>24.99</double></value> </param> </params> </methodResponse> |
从清单 4 可以看出,methodResponse封装了getBookPrice的调用结果,在HTTP上,它作为HTTP response的body返回回来。
REST over HTTP
REST风格的架构也并不强调和协议的绑定。HTTP是WWW网上广泛使用的并且被证明是有效的通信协议,所以现在RESTful服务基本也是基于HTTP协议的。资源是由URI来指定。
对资源的操作包括获取、创建、修改和删除资源,这些操作正好对应HTTP协议提供的GET、POST、PUT和DELETE方法。通过操作资源的representation来操作资源。资源的representation可以是XML也可以是HTML,取决于读者是机器还是人,是消费web服务的客户软件还是 web 浏览器。当然也可以是任何其他的格式。清单 5 和清单 6 给出REST over HTTP的request和response的示例。
清单 5. A REST Request over HTTP示例
| 以下是引用片段: GET /books/123456/xml HTTP/1.1 Host: example.com |
清单 6. A REST Response over HTTP示例
| 以下是引用片段: HTTP/1.1 200 OK Date: Fri, 10 Sept 2010 17:15:33 GMT Last-Modified: Fri, 10 Sept 2010 17:15:33 GMT ETag: “2b3f6-a4-5b572640” Accept-Ranges: updated Content-Type: text/xml; charset=”utf-8″ <book category=”CHILDREN”> <title lang=”en”>Harry Potter</title> <author>J K. Rowling</author> <year>2005</year> <price>24.99</price> </book> |
从清单 5 和清单 6 种,可以清楚的看到,REST在最大程度上充分利用了HTTP,没有增加额外的词汇和约定。
通过前面的分析和比较,我们可以清楚地看到,REST风格的web服务与SOAP RPC和XML RPC风格的web服务相比,http request更简单,response 的语意更清楚。而且客户端不需要知道那么多关于应用的细节,比如method name,method调用的参数等等。
简言之,目前在三种主流的Web服务实现方案中,因为REST模式的Web服务与复杂的SOAP和XML-RPC对比来讲明显的更加简洁,越来越多的web服务开始采用REST风格设计和实现。例如,Amazon.com提供接近REST风格的Web服务进行图书查找;雅虎提供 Web服务也是REST风格的。
REST风格的web服务已被广泛的接受和使用,但是在使用的过程中,我们发现其实有很多号称RESTful的web服务并不是Roy定义的REST服务,或者违背了其中的一些约束。像Amazon和Flickr的web服务。接下来,我们首先结合实际经验,重新解读REST架构风格中的核心概念,帮助读者准确的掌握REST架构,最后给出一个完全符合REST风格架构的web服务定义的例子。
REST核心概念解读
Representational State Transfer
在理解REST相关的核心概念之前,我们来看看“REST”本身应该怎么理解。“Representational State Transfer”是一个不完整的句子,“Representational”代表的是什么的“表示”?“State”又指的是什么的状态 ?“Transfer”的又是什么?如果我们要把它补全该如何呢?根据Roy的论文和我们的实践,应该是“Application States Transfer among the resource ’ s representation”。这里的“State”指的是“应用”的“状态”,这个“状态”是用“资源的表示”来代表的,用户可以在“状态”之间“跳转”。
REST架构风格定义的约束
REST是一种架构的风格,它是对分布式hypermidea系统的架构元素的抽象,提供了一些核心的概念和指导思想。这种架构风格是“客户端 – 服务器”架构风格的一种,也就是说“客户端”发起“请求”,“服务器”处理“请求”并返回相应的结果。REST的贡献是规定了一系列的方法论,在“请求”方面,规定“客户端”怎么发起“请求”,发的是什么样的“请求”,以什么协议发“请求”;在处理方面,规定“服务器”怎么响应“请求”,返回什么样的“响应”,系统后续应该怎么“跳转”等等。让我们再回顾Roy定义的这些约束。
“无状态”(Stateless)
“客户端”和“服务器端”的交互是“无状态”的,也就是说“请求”之间是相互隔离的。“服务器端”不保存“客户端”的应用上下文(context),每个从“客户端”来的“请求”都必须包括所有的必要的信息让“服务器端”能够完全理解“请求”并处理。“客户端”存了很多“会话”的信息。让我们以搜索引擎为例来看看“有状态”和“无状态”的区别。图 1 和图 2 分别给出了两个搜索引擎的“有状态”和“无状态”的交互示例。
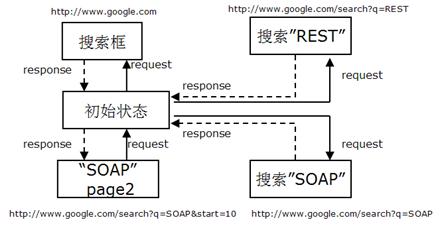
图 1. 无状态的搜索引擎的交互示例
图 1 所示是无状态的搜索引擎的请求(request)和响应(response)的实例。可以清楚地看出,每个request和response都是互相独立的,相互之间没有数据的依赖。每个request包含服务器端响应这个 request 所需要的所有信息。 以“搜索SOAP”为例,用户首先发了request http://www.google.com/search?q=SOAP,并且得到了搜索结果,其中包含了10个最相关的搜索结果。这个交互过程就结束了,服务器端没有保存任何和这个请求相关的信息。但是在这个返回的状态中,服务器端把下一步的可能的状态嵌在其中了。比如用户如果在这些结果没有找到自己想要的结果,他可以翻页,翻到第二页。第二页是另一个状态,这时用户点击了第二页,然后客户端又发了一个request http://www.google.com/search?q=SOAP&start=10,这个request了包含了所有的上下文,也就是“按关键字SOAP搜索并且以第10个搜索结果开始返回”。也就是说,服务器把当前的状态隐含中结果中返回,客户端保存下这些隐含的状态,而不是保存在服务器端。客户端可以根据服务器端返回来的状态构建下一个状态的请求。
“无状态”的好处是每个状态都有一个对应的URI,这些URI可以bookmark,可以使得用户方便的在浏览器中前进后退,可以在用户希望的任何时候访问任意多次。
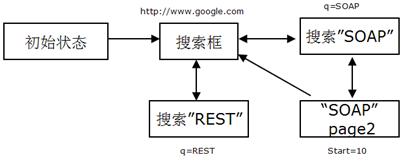
图 2. 有状态的搜索引擎的交互示例
图 2 是有状态的搜索引擎的request和response的交互示例。可以看出,request 之间的时序依赖性。以“搜索SOAP”为例,用户在看 1~10 个搜索结果并想看 11~20 个结果,客户端只需要发一个“start=10”的请求而是发“/search?q=SOAP&start=10”的请求,也就是客户端不用重复前面的request的上下文。这使得 HTTP request 相对简单了很多。但是他使得HTTP protocol变得复杂。服务器端和客户端需要同步会话的状态,在可靠网络上,这是一个复杂的任务。
“无状态”带来了一些性能的提升。在“visibility”方面,对于监控系统而言,它不用去关心跨请求的数据对当前请求的影响,所以“visibility”有所提升。在“reliability”方面,由于“客户端”保存了很多“会话”数据,因此减少了部分“服务器”端的故障或者网络故障对应用的影响,因此对于用户来说,“reliability”有所提升。最值得一提的是“scalability”,由于“服务器”端能够独立的响应每个 request,而不用依赖会话历史,因此少了很多“资源”的管理和同步,使得多个服务器可以同时服务不同的用户的请求,获得很好的自由扩展功能。
当然,事务都有两面性,“无状态”带来的不足之处包括可能的网络性能的降低,因为“服务器”会发很多重复的数据到不同的“客户端”,使得“客户端”保存所有的会话信息;这也导致了另一个问题,就是“服务器”将失去对应用的一致行为的一部分控制权,而且还对“客户端”的实现产生依赖。
“缓存”(Cacheable)
为了提高REST风格架构的网络性能,Roy加入了“缓存”的约束。“缓存”不是一个新的概念,HTTP协议提供机制,使得“客户端”可以“缓存”一些数据。在“服务器”返回的“响应”中,可以隐式或者显式的指明数据的“缓存”属性,这样,“客户端”可以在未来使用“缓存”下来的数据,减少“客户端”和“服务器”端的交互次数,从而达到提高网络性能的目的。
统一的接口(Uniform Interface)
这是REST风格的架构区别于其他架构的一个最关键的指标,就是 REST 风格的架构对于任意应用,规定了统一的接口定义。接口定义包括四个部分:
1)identification of resources(标识资源);
2)manipulation of resources through representations(通过资源的表示来操作资源);
3)self-descriptive messages(自描述的信息);
4)hypermedia as the engine of application state(超媒体作为应用状态的引擎)
下面分别对这些概念进行解析。
Identification of resources
第一部分“identification of resources”讲了REST架构风格的一个最核心的概念“Resource”以及 “Resource”的“identification”。“Resource”是信息系统的一种抽象,可以是任何重要的足以把本身作为一个引用(reference)的事物。从应用的角度看,如果应用的用户需要“创建一个到它链接”,获取或者缓存它的“表示”,或者想对他做些操作,那么都可以创建一个“Resource”。一个“Resource”可以是现实世界的事物,比如一本书,一辆车,一栋房子;也可以是一个虚拟的概念,也可以是一个算法的结果。“identification”是“Resource”的全局唯一的标识,如果“Resource”没有 identification,那么他不能称为“Resource”。用URI来表示一个 Resource 的 identification。关于URI的最佳实践包括URI是自描述的,有结构的,这样可以使得“客户端”可以自己创建一些有预测性的请求。几个比较好的Resource URI示例:
- http://www.example.com/books/123456
- http://www.example.com/softwares/im/db2/9.5
- http://www.example.com/blog/2010/09/10/1
- http://www.example.com/bugs/by-state/new
前面解释了什么是Resource,怎么用URI来标识一个Resource,下面来看下Resource和URI的关系,他们之间是不是一一对应的呢?让我们来回答下面几个问题:1)两个 URI 能指向同一个Resource 么?回答是肯定的。作为程序员,我们都有这样的经历,就是经常做一些release,让我们考虑这两个 URI: http://www.example.com/releases/3.1.1 和 http://www.example.com/releases/latest,在特定的时刻,他们指向的就是同一个resource,但是背后的概念是不一样的,一个是指向一个特定的release版本号,一个是指向一个随着时间演进的resource,是两个完全不同的概念。所以一个resource可以有一个或者多个URI来标识。2)一个URI能指向不同的resource么?答案是否定的。这和 Universal Resource Identifier的原则相违背。
Manipulation of resources through representations
接着来看看“Representation”。Representation是Resource的表现形式。Resource是信息系统的抽象,但是最终必须以人们能理解的一种形式提供出来。可以是一个XML文档,HTML文档,CSV,file等等。一个Resource可以有多种Representation。那么服务器端怎么知道用户想要哪个 Representation 呢?通常来讲有两种方式:
1)在resource 的URI里面指明,为不同的Representation 提供不同的 URI。举个例子,我们有个book的resource,我们提供几个不同的 URI 来表示不同的representation。清单7、8、9分别是XML、JSON、CSV三种representation的HTTP request和response的示例。
清单 7. Representation为XML的request和response示例
| 以下是引用片段: GET /books/123456/xml HTTP/1.1 Host: example.com Reponse: HTTP/1.1 200 OK Date: Fri, 10 Sept 2010 17:15:33 GMT Last-Modified: Fri, 10 Sept 2010 17:15:33 GMT ETag: “2b3f6-a4-5b572640” Accept-Ranges: updated Content-Type: text/xml; charset=”utf-8″ <book category=”CHILDREN”> <title lang=”en”>Harry Potter</title> <author>J K. Rowling</author> <year>2005</year> <price>24.99</price> </book> |
清单 8. Representation为JSON的request和response示例
| 以下是引用片段: GET /books/123456/json HTTP/1.1 Host: example.com Reponse: HTTP/1.1 200 OK Date: Fri, 10 Sept 2010 17:15:33 GMT Last-Modified: Fri, 10 Sept 2010 17:15:33 GMT ETag: “2b3f6-a4-5b572640” Accept-Ranges: updated Content-Type: text/json; charset=”utf-8″ [ “book”: { “title”:Harry Potter, “author”:J K. Rowling, “year”:2005, “price”:24.99 } ] |
清单 8. Representation为CSV的request和response示例
| 以下是引用片段: GET /books/123456/csv HTTP/1.1 Host: example.com Reponse: HTTP/1.1 200 OK Date: Fri, 10 Sept 2010 17:15:33 GMT Last-Modified: Fri, 10 Sept 2010 17:15:33 GMT ETag: “2b3f6-a4-5b572640” Accept-Ranges: updated Content-Type: text/csv; charset=”utf-8″ title,author,year,price Harry Potter,J K. Rowling,2005,24.99 |
2) 利用HTTP的内容协商(content negotiation)机制。客户端可以利用“Accept”header 指明它希望的内容表示形式。还是拿book的例子来说,客户端发的HTTP请求如清单 9 所示:
清单 9. 利用content negotiation机制请求representation的request示例
| 以下是引用片段: GET /books/123456 HTTP/1.1 Host: example.com Accept: text/xml GET /books/123456 HTTP/1.1 Host: example.com Accept: text/json GET /books/123456 HTTP/1.1 Host: example.com Accept: text/csv |
对应的response和第一种方式相同,所以忽略了。
相比较这两种方式,根据我们的经验,第一种方式更好,URI是一种好的实践,用来表示resource的各方面的信息,包括结果,版本,representation形式,时间等等,它带来的好处是使客户端的工作大大降低,它很方便的可以在不同的应用之间共享。
那么怎么对 resource 进行下一步的操作(“manipulation”)呢? REST对Resource的操作定义和HTTP method是对应起来的。HTTP协议定义 GET、POST、PUT、DELETE 来表示对资源的获取、创建、更新和删除。“Manipulation of resources through representations”约束规定了 resource 的操作是通过 representation 来完成的,所以在resource的representation里面,需要包含对resource的操作怎么进行。APP(ATOM Publishing Protocol)提供了一个最佳实践,是用 <link> 的方式指明Resource响应的操作,下面是一个实例:
| 以下是引用片段: <link rel=”edit” href=”http://www.example.com/books/123456″/> |
rel定义了该link的resource和当前resource的关系,href定义了resource的HTTP endpoint。所以当用户想更新id为123456的book的价钱的时候,客户端会发一个PUT请求到指定的URI,示例如清单 10 所示:
清单 10. 更新resource的request示例
| 以下是引用片段: PUT /books/123456 HTTP/1.1 Host: example.com Reponse: HTTP/1.1 200 OK Date: Fri, 10 Sept 2010 17:15:33 GMT Last-Modified: Fri, 10 Sept 2010 17:15:33 GMT <book category=”CHILDREN”> <title lang=”en”>Harry Potter</title> <author>J K. Rowling</author> <year>2005</year> <price>31.99</price> </book> |
同样,客户端可以发HTTP请求去删除这个book,如清单 11 所示。
清单 11. 删除resource示例
| 以下是引用片段: DELETE /books/123456 HTTP/1.1 Host: example.com Reponse: HTTP/1.1 200 OK |
Self-descriptive messages
REST接口的定义强调了自描述“Self-descriptive”性。自描述性也是为了让客户端充分的理解当前的状态,下一步的状态怎么跳转。
前面讲了resource的representation,只讲述了representation的数据的一部分。在representation里面,除了包含数据部分,还包括元数据,它是用来描述数据的信息,或者是一些客户端需要知道的一些领域知识。这里以ATOM协议为例看看怎么在representation里面提供自描述的信息。清单 12 是一个ATOM的片段。
清单 12. 一个ATOM形式的resource representation
| 以下是引用片段: <?xml version=”1.0″ encoding=”UTF-8″?> <feed > <id>urn:uuid:60a76c80-d399-11d9-b93C-0003939e0af6 </id> <link href=”http://www.example.com/books?q=harry potter&start=0″ rel=”self”></link> <link href=”http://www.example.com/books?q=harry potter&start=10″ rel=”next”></link> <updated>2009-08-11T03:00:27.062Z</updated> <title type=”text”> harry potter 相关的图书 </title> <os:startIndex >0</os:startIndex> <os:itemsPerPage >10</os:itemsPerPage> <os:totalResults >10</os:totalResults> <entry> <title type=”text”> Harry Potter </title> <id>urn:id:23-27</id> <updated>2009-07-09T11:01:26.000Z</updated> <category term=”harry potter”></category> <category term=”best seller”></category> <category term=”book”></category> <category term=”Hyper Service”></category> <content type=”application/xml” > <title lang=”en”>Harry Potter</title> <author>J K. Rowling</author> <year>2005</year> <price>31.99</price> </book> </content> </entry> … </feed> |
从上面的例子可以看出,除了<content>里面的内容是和book数据相关的信息以外,剩下的信息都是描述性的信息,通常包括翻页信息:一共有多少页,前后翻页的link是什么;分类信息,时间信息,还有一些文本信息供用户阅读。
总之,服务器端尽可能的返回详细的信息,帮助客户端理解当前的状态,以及发起下一个请求所需要的所有信息,以达到“服务器端无状态”和客户端发起“状态跳转”的目的。
Hypermedia as the engine of application state
“Hypermedia as the engine of application state”是“统一接口”的最后一个约束,也是最重要的一个约束,不幸的是, Roy的REST论文中对这个约束的解释特别少,在这里,我们根据我们的经验和理解,对这个约束进行描述。这个约束其实规定的是应用系统是通过Hypermedia的方式在不同的状态之间跳转。这句话听起来有点拗口,还是来看一个例子吧。
Flickr提供了REST API,以flickr.groups.members.getList为例来看看这个REST API的 定义,清单 13 是一个响应示例(sample response),可以看出“members”是一个resource,它是一系列“member”的集合,也就是说,它指向其他的resource。
清单 13. flickr.groups.members.getList的响应示例
| 以下是引用片段: <members page=”1″ pages=”1″ perpage=”100″ total=”33″> <member nsid=”123456@N01″ username=”foo” iconserver=”1″ iconfarm=”1″ membertype=”2″/> <member nsid=”118210@N07″ username=”kewlchops666″ iconserver=”0″ iconfarm=”0″ membertype=”4″/> <member nsid=”119377@N07″ username=”Alpha Shanan” iconserver=”0″ iconfarm=”0″ membertype=”2″/> <member nsid=”67783977@N00″ username=”fakedunstanp1″ iconserver=”1003″ iconfarm=”2″ membertype=”3″/> … </members> |
如果用户还想对“Alpha Shanan”了解更多呢?这时,客户端会构建一个HTTP request,URI为:http://api.flickr.com/services/rest/?method=flickr.people.getInfo?auth_key=xxxx&user_id=119377@N07
如果系统按照这种方式运行,问题在哪呢?客户端和服务器端需要有很多的共享的知识和约定,客户端需要知道获取人员信息的API是 method=flickr.people.getInfo以user_id作为参数。这不是Hypermedia,同时也违背了Roy的关于“Hypermedia as the engine of application state”的约束,所以这个不是好的RESTful的实现。
Hypermedia的实质是hyperlink, 用hyperlink把这些相互依赖的resource联系起来,这些hyperlink是由服务器端生成并且在representation里面返回来的,包括了当前的状态集合和可能的下一步的状态集合。客户端不需要任何domain specific知识就能够实现状态的跳转。Hypermedia类型的sample response如清单 14 所示。在清单 14 中可以看到,resource和resource之间的联系通过hyperlink关联起来,并且在resource的representation里面表示。
清单 14. REST风格的flickr.groups.members.getList的sample response
| 以下是引用片段: <members page=”1″ pages=”1″ perpage=”100″ total=”33″> <member href=” http://api.flickr.com/services/rest/? method=flickr.people.getInfo?auth_key=xxxx&user_id=123456@N01″ username=”foo” iconserver=”1″ iconfarm=”1″ membertype=”2″/> <member href=” http://api.flickr.com/services/rest/? method=flickr.people.getInfo?auth_key=xxxx&user_id=118210@N07″ username=”kewlchops666″ iconserver=”0″ iconfarm=”0″ membertype=”4″/> <member href=” http://api.flickr.com/services/rest/? method=flickr.people.getInfo?auth_key=xxxx&user_id=119377@N07″ username=”Alpha Shanan” iconserver=”0″ iconfarm=”0″ membertype=”2″/> <member href=” http://api.flickr.com/services/rest/? method=flickr.people.getInfo?auth_key=xxxx&user_id=67783977@N00″ username=”fakedunstanp1″ iconserver=”1003″ iconfarm=”2″ membertype=”3″/> … </members> |
通过前面关于“统一接口”的解析,我们清楚地知道,REST风格的架构使得web服务的“客户端”和“服务器端”很好的分离开来。“客户端”不需要关心数据的存储,使得“客户端”的可移植性(portability)提高了。“服务器端”不用关心用户的接口和用户的状态,所以“服务器端”将变得更加简单,而且方便的获得更好的可伸缩性(scalability)。只要保持接口的定义不变 ,“客户端”和“服务器端”可以独立的开发和演变。
一个定义良好的RESTful Web服务接口
首先,用一个文档描述web服务的capabilities以及服务的location。如清单 15 所示。
清单 15. 用APP协议描述的服务capabilities和location
| 以下是引用片段: <?xml version=”1.0″ encoding=”UTF-8″?> <service > <workspace> <atom:title type=”text”> InfoSphere MashupHub </atom:title> <collection href=”http://localhost:8080/mashuphub/atom?collection=all”> <atom:title type=”text”> All </atom:title> <accept> application/atom+xml; type=entry </accept> <categories> <categories> ALL </categories> </categories> </collection> <collection href=”http://localhost:8080/mashuphub/atom?collection=feeds”> <atom:title type=”text”>Feeds</atom:title> <accept> application/atom+xml;type=entry </accept> <categories> <categories> feeds </categories> </categories> </collection> … </workspace> </service> |
这个服务文档指明InfoSphere MashupHub提供了一系列的web服务,包括list所有的资源,list所有的feeds等等。并且还描述了每个web服务的 location可以提供的resource representation的类型。这种描述文档对于web服务的客户端来说非常有益。这个服务描述文档本身也是一个 resource,可以用HTTP URI定位到。
其次,我们来看一下每个web服务是怎么定义的。
清单 16. RESTful web服务接口的定义示例
1) Resource:所有的 feeds
2) Resource URI:http://localhost:8080/mashuphub/atom?collection=feeds
3) Resource representation:
| 以下是引用片段: <feed > <id> http://9.186.64.113:8080/mashuphub/atom?collection=feed </id> <link href=”http://9.186.64.113:8080/mashuphub/atom?collection=feeds” rel =”self”></link> <updated> 2010-09-11 T 15:12:24.968Z </updated> <title type = “text”> feeds Collection </title> <author> <name> InfoSphere MashupHub Search Feed</name> </author> <entry> <author> <name> InfoSphere MashupHub Search Feed </name> </author> <title type=”html”> MyCo Customer List </title> <updated> 2010-09-07 T 05:08:52.000Z </updated> <id> urn:id:1460 </id> <link href=”http://9.186.64.113:8080/mashuphub/atom?collection=feeds&id=1460″ rel=”self”></link> <link href=”http://9.186.64.113:8080/mashuphub/atom?collection=feeds&id=1498″ rel=”related” title = “MyCo Customer List with weather info” > </link> <category term=”feed”> </category> <content type = “application/xml” > <catalog:feed > <catalog:version> 1.0 </catalog:version> <catalog:name> MyCo Customer List </catalog:name> <catalog:author> admin </catalog:author> <catalog:permission> public </catalog:permission> <catalog:description> </catalog:description> <catalog:rating> 0.0 </catalog:rating> <catalog:useCount> 320 </catalog:useCount> <catalog:dateModified> 1283836132 </catalog:dateModified> <catalog:numComments> 0 </catalog:numComments> <catalog:tags> </catalog:tags> <catalog:categories> </catalog:categories> <catalog:downloadURL>http://9.186.64.113:8080/mashuphub/client /plugin/generate/entryid/1460/pluginid/3 </catalog:downloadURL> <catalog:mimetype> application/atom+xml </catalog:mimetype> </catalog:feed> </content> </entry> </feed> |
4) Http method: GET
5) 和别的resource的关系。
在representation中用 <link>
定义了“MyCo Customer List”和“MyCo Customer List with weather info”的关系
总结一下,一个设计良好的RESTful web服务应该包括一下几个定义:
1) 服务描述文档,如清单 15 所示;
2) 资源 (resource) 及其identification;
3) 资源的representation的定义
4) 用HTTP method表示的资源的manipulation
5) 在资源的representation里面以Hyperlink表述的资源和资源之间的关系
结束语
REST是一种架构风格,汲取了WWW的成功经验:无状态,以资源为中心,充分利用HTTP协议和URI协议,提供统一的接口定义,使得它作为一种设计Web服务的方法而变得流行。在某种意义上,通过强调URI和HTTP等早期Internet标准,REST是对大型应用程序服务器时代之前的Web方式的回归。
本文根据Roy的论文,结合实际的例子,重新解析了REST中的核心概念。根据作者多年的创建和使用RESTful web服务的经验,更多的是在观念上的澄清。最后通过一个RESTful web服务,告诉读者一个真正意义上的RESTful web服务是什么样子。但愿本文的讨论会您提供了一定意义上的思想上的指导和实践上的指导。
我们一直都在努力坚持原创.......请不要一声不吭,就悄悄拿走。
我原创,你原创,我们的内容世界才会更加精彩!
【所有原创内容版权均属TechTarget,欢迎大家转发分享。但未经授权,严禁任何媒体(平面媒体、网络媒体、自媒体等)以及微信公众号复制、转载、摘编或以其他方式进行使用。】
微信公众号

TechTarget
官方微博

TechTarget中国
作者
相关推荐
-
SAP收购CallidusCloud 与Salesforce竞争
一直被称为后台办公巨头的SAP现在似乎也想在前台办公大展拳脚。 最新的迹象是SAP收购CallidusClou […]
-
API开发与管理大作战
2014将会是API管理方法新旧PK的一年,据Delyn Simons说,她领导了Mashery开发者的外展团队。应用编程接口(API)的主流化和私有化在新的一年也将掀起波澜,她在波士顿“Future Insights Ultimate Developer Event 2013”大会上预测说。
-
公共API外包管理是否值得考虑?
公共API外包管理是指聘请一个专家小组来解决可扩展性问题,同时也提出几套可替代的方案。
-
API设计如龙生九子 各不相同
IT咨询管理公司CA Technologies对API产业做了个问卷调查,问卷内容涉及API设计风格以及管理部署的新动向。调查结果表明,JSON与XML可谓两分天下。